These are the experiments whose results you have to hear. The full evaluation (latency, throughput, cross-GPU benchmarks, quality metrics) is in the paper; a handful of findings, though, only really land as audio. Each isolates one property of the engine: streaming parity, per-frame SDE source preservation on a shared asymptotic curve, per-tick scalar denoise on the same curve, per-slot continuity vs. a global-reset baseline, and a per-frame latent morph driven through the shared mutable state.
Streaming pipeline does not degrade quality
Bit-identical 8-step latents decoded two ways. The batch path runs a single full 60 s VAE decode; the stream path replays the same latents tick-by-tick through a 5 s windowed decode, mirroring the live pipeline. Same fixture (low-fi loop), deathstep LoRA active in both.
Per-frame source preservation on a 1 − t³ curve
The shared asymptotic curve below, driven into the SDE step's per-frame source-preservation parameter at the latent's 25 Hz frame resolution. The model runs free for most of the clip, then lands back on the source-anchored side in the final seconds. One generation per fixture, each with its paired LoRA.
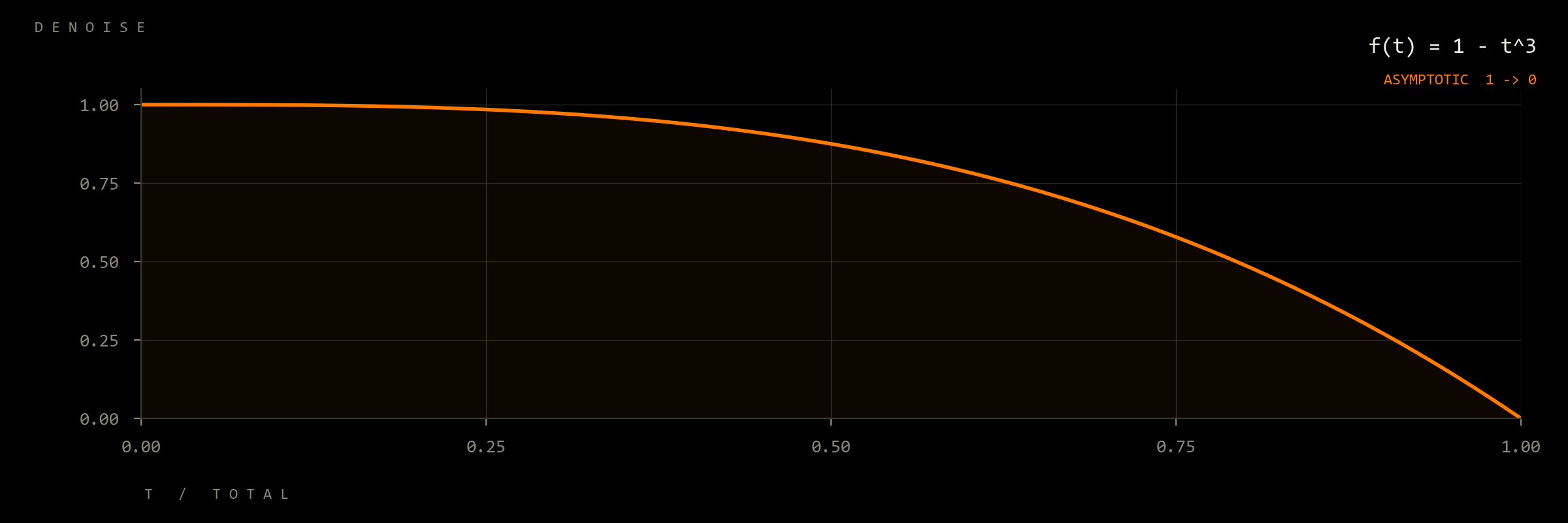
Per-tick scalar denoise on the same 1 − t³ curve
Same trajectory, different lane: the streaming pipeline's per-tick scalar denoise input is driven along 1 − (k/N)³ instead of the per-frame SDE parameter. One fresh 0.3 s playback chunk per tick. Holds the model's free response (denoise ≈ 1.0) for most of the run and collapses back to the source as the sweep ends.
Heterogeneous per-slot scheduling vs. global reset
Illustrative pair built around a denoise switch (1.0 → 0.5). Under DEMON's per-slot scheduling the output stays continuous across the drain; a StreamDiffusion-style global reset incurs ~648 ms of dead air while the depth = 8 ring buffer refills. Matches the 60/60 vs. 1/60 completion-rate result in the paper.
Per-frame latent morph between two cover variants
Two cover variants of one source, A (deathcore) and B (ambient), share seed and structure, so their latents stay aligned. The x0_target_strength field, read from the same shared mutable registry every slot consults each step as the SDE curve, is driven as the per-frame swell below: it blends each frame's x0 prediction toward B's precomputed latent, gated to the refinement half of the schedule. The song swells from A into B and back, in a single generation. The blend is convex between two clean latents, so it stays inside the manifold: no re-noising, no artifact.
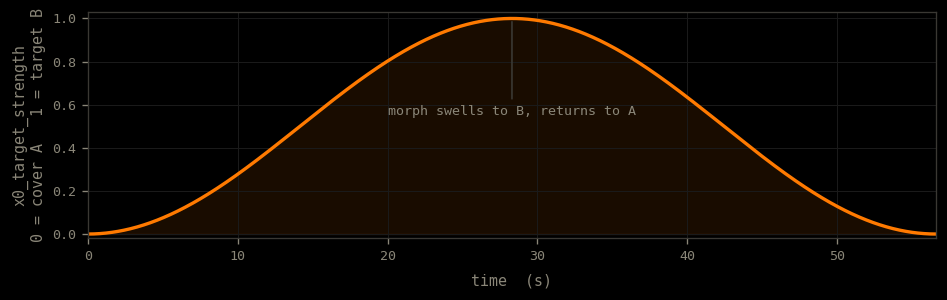
x0_target_strength swell — written once into the shared registry, read by every in-flight slot on every step; convex blend toward target B.